
Task Lift
In robotic visuomotor policy learning, diffusion-based models have achieved significant success in improving the accuracy of action trajectory generation compared to traditional autoregressive models. However, they suffer from inefficiency due to multiple denoising steps and limited flexibility from complex constraints. In this paper, we introduce Coarse-to-Fine AutoRegressive Policy (CARP), a novel paradigm for visuomotor policy learning that redefines the autoregressive action generation process as a coarse-to-fine, next-scale approach. CARP decouples action generation into two stages: first, an action autoencoder learns multi-scale representations of the entire action sequence; then, a GPT-style transformer refines the sequence prediction through a coarse-to-fine autoregressive process. This straightforward and intuitive approach produces highly accurate and smooth actions, matching or even surpassing the performance of diffusion-based policies while maintaining efficiency on par with autoregressive policies. We conduct extensive evaluations across diverse settings, including single-task and multi-task scenarios on state-based and image-based simulation benchmarks, as well as real-world tasks. CARP achieves competitive success rates, with up to a 10% improvement, and delivers 10× faster inference compared to state-of-the-art policies, establishing a high-performance, efficient, and flexible paradigm for action generation in robotic tasks.
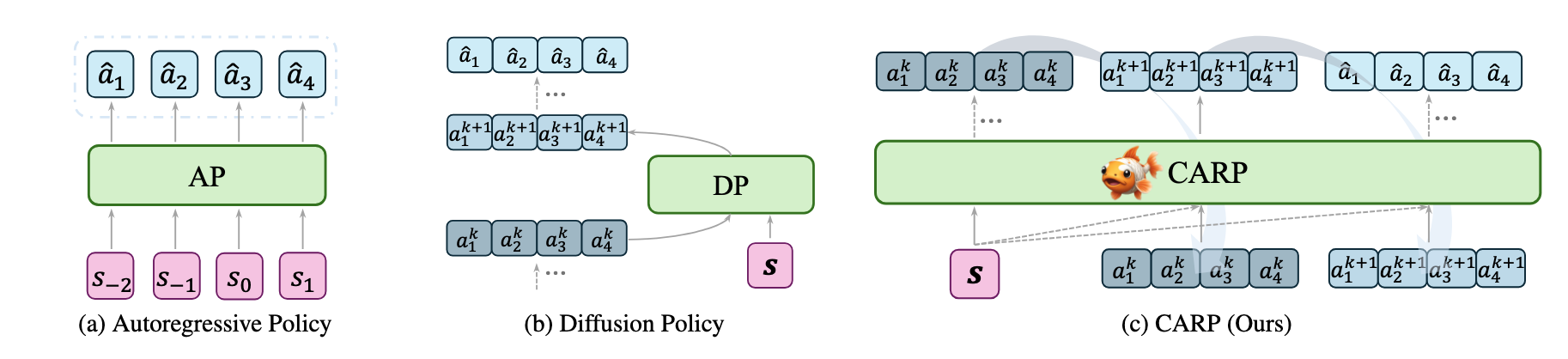
(a) Autoregressive Policy predicts the action step-by-step in the next-token paradigm.
(b) Diffusion Policy models the noise process used to refine the action sequence.
(c) CARP refines action sequence predictions autoregressively from coarse to fine granularity.
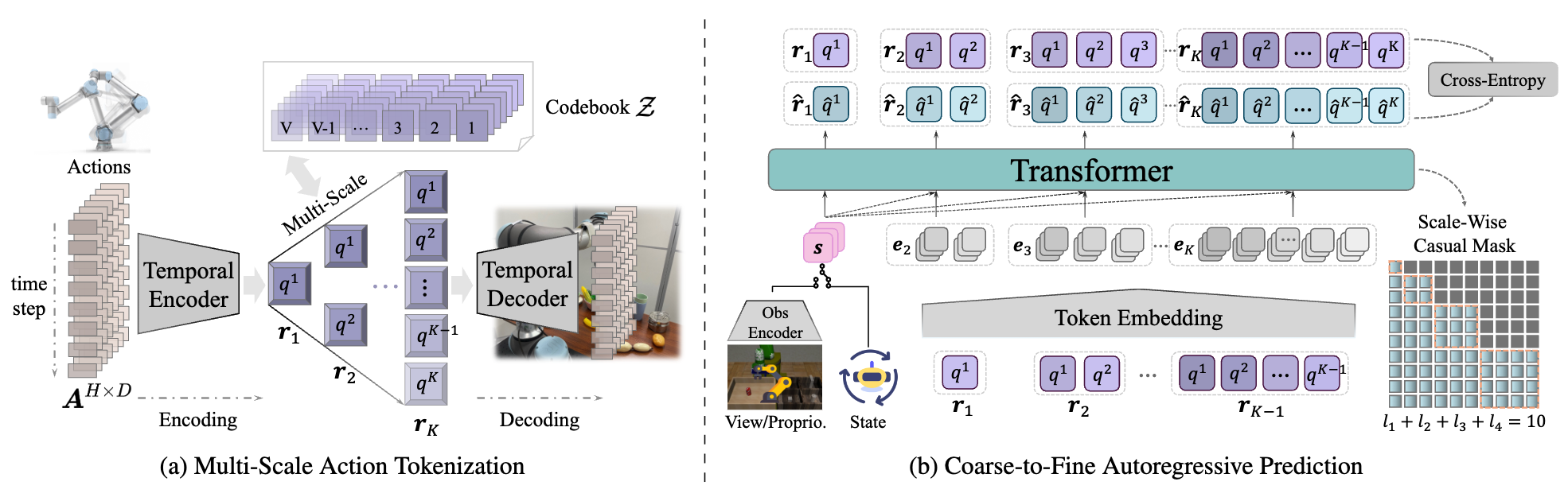
Coarse-to-Fine Autoregressive Prediction : The autoregressive prediction is reformulated as a coarse-to-fine, next-scale paradigm. The sequence is progressively refined from coarse token map \( {r}_1 \) to finer granularity token map \( {r}_K \), where each \( {r}_k \) contains \( l_k \) tokens. An attention mask ensures that each \( {r}_k \) attends only to the preceding \( {r}_{1:k-1} \) during training. $$ \begin{equation} p({r}_1, {r}_2, \dots, {r}_K) = \prod_{k=1}^{K} p({r}_k \mid {r}_1, {r}_2, \dots, {r}_{k-1};{s}_O), \end{equation} $$
Task Lift

Task Can

Task Square

Task Kitchen
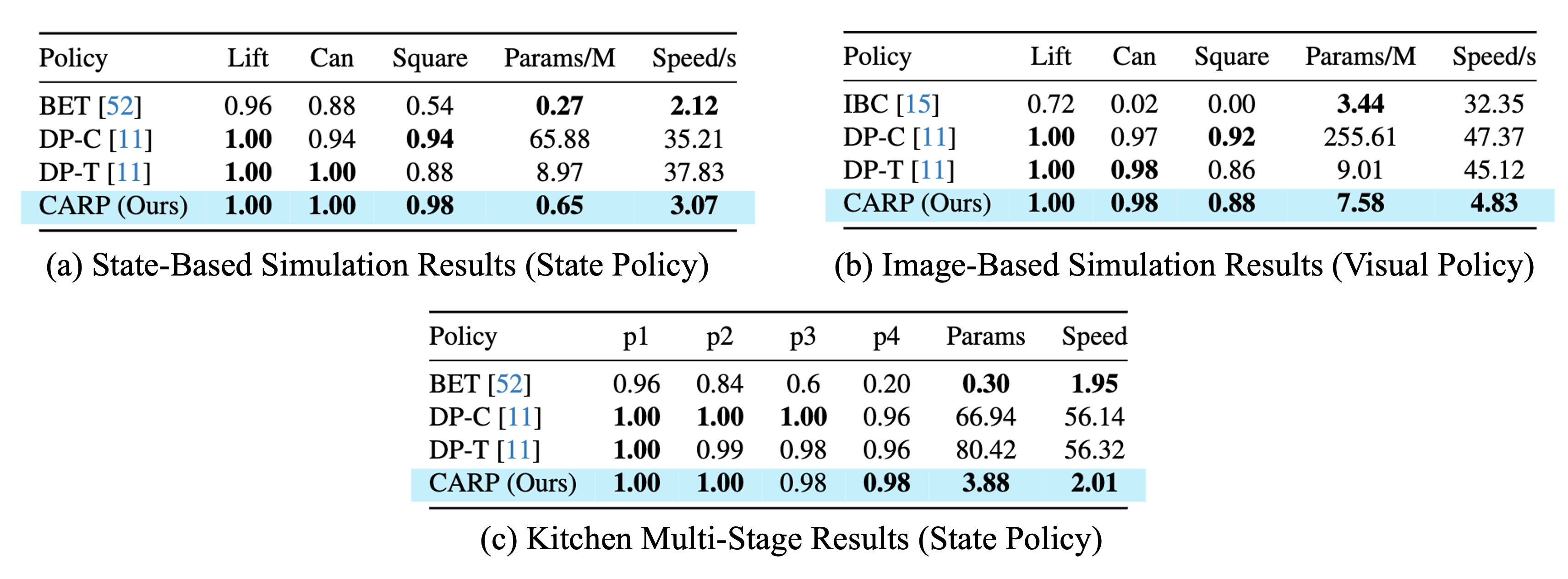
We report the average success rate of the top 3 checkpoints, along with model parameter scales and inference time, with our results highlighted in light-blue. CARP significantly outperforms BET, especially on challenging metrics like and Square p4 in Kitchen, and achieves competitive performance with state-of-the-art diffusion models, while also surpassing DP in terms of model size and inference speed (supporting RQ1 and RQ2).
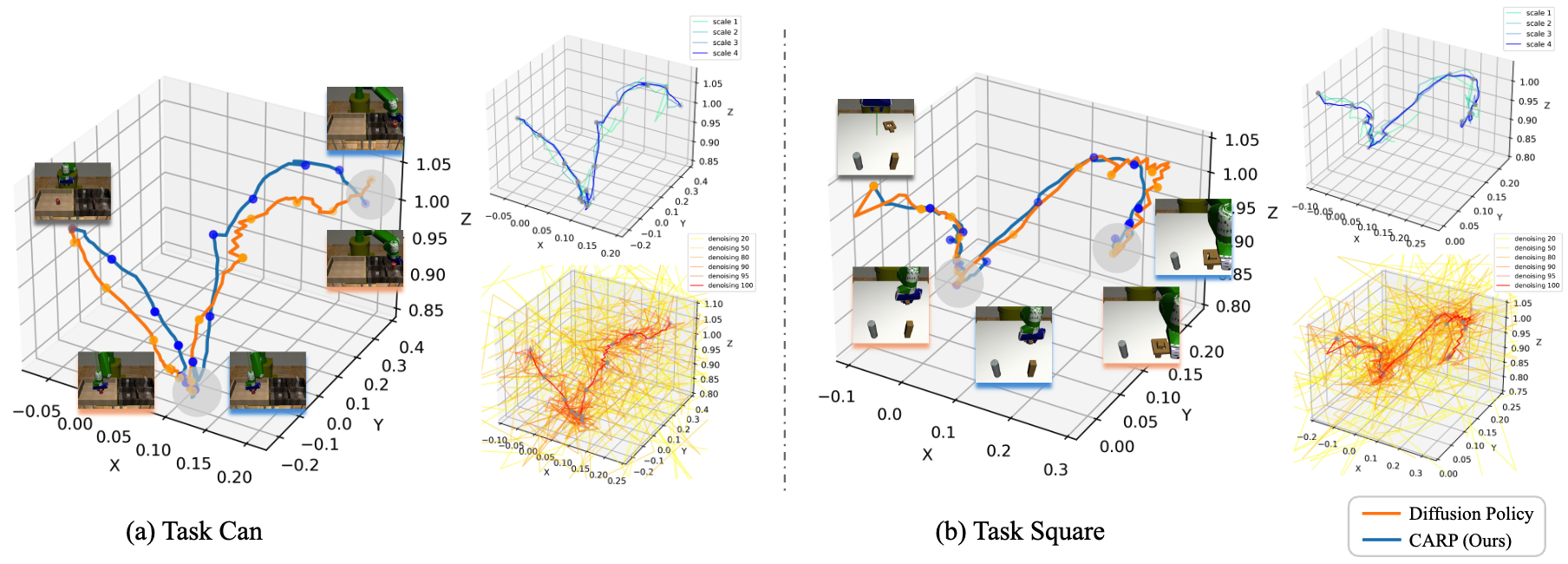
Visualization of the Trajectory and Refining Process. The left panel shows the final predicted trajectories for each task, with CARP producing smoother and more consistent paths than Diffusion Policy (DP). The right panel visualizes intermediate trajectories during the refinement process for CARP (top-right) and DP (bottom-right). DP displays considerable redundancy, resulting in slower processing and unstable training, as illustrated by 6 selected steps among 100 denoising steps. In contrast, CARP achieves efficient trajectory refinement across all 4 scales, with each step contributing meaningful updates.

Coffee

Hammer Cleanup

Mug Cleanup

Nut Assembly

Square

Stack

Stack Three

Threading

CARP achieves up to a 25% average improvement in success rates compared to state-of-the-art diffusion-based policies, highlighting its strong performance. Additionally, CARP achieves over 10× faster inference speed and uses only 10% of the parameters compared to SDP. With minimal modification, CARP seamlessly transitions from single-task to multi-task learning, further demonstrating its flexibility, a benefit of its GPT-style architecture (supporting RQ3).
Diffusion Policy
CARP
Diffusion Policy
CARP
We visualize the action prediction and execution of Diffusion Policy and CARP in the left panel, using the same prediction horizon and execution length (with a 4x speed-up for quicker viewing). CARP demonstrates faster execution due to its higher inference speed. In the right panel, we test both policies on a moving object; CARP maintains better alignment with the object thanks to its faster response time.
CARP achieves comparable or superior performance, with up to a 10% improvement in success rate over the diffusion policy across all real-world tasks (supporting RQ1). Additionally, CARP achieves approximately \( 8\times \) faster inference than the baseline on limited computational resources, demonstrating its suitability for real-time robotic applications (supporting RQ2).
@misc{gong2024carpvisuomotorpolicylearning,
title={CARP: Visuomotor Policy Learning via Coarse-to-Fine Autoregressive Prediction},
author={Zhefei Gong and Pengxiang Ding and Shangke Lyu and Siteng Huang and Mingyang Sun and Wei Zhao and Zhaoxin Fan and Donglin Wang},
year={2024},
eprint={2412.06782},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2412.06782},
}